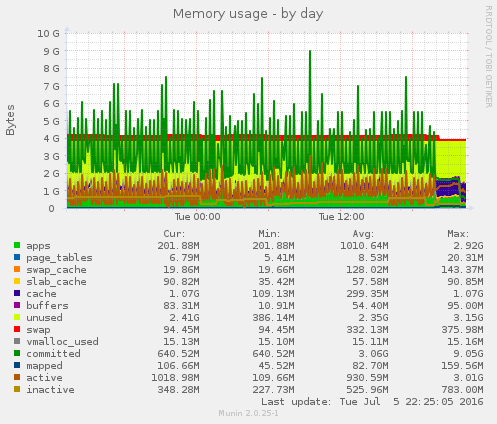
SSDs haben das Problem, dass die Speicherzellen nur eine begrenzte Anzahl Schreibvorgänge vertragen. Danach sind sie kaputt. Zwar hat jede SSD eine Reserve, die in so einem Fall automatisch benutzt wird, aber die hält eben auch nicht ewig. Durch unachtsame Konfiguration kann man so ganz schnell seine Hardware schrotten.
Im folgenden Beispiel wurden die SMART-Werte zweier im RAID1-Verbund laufender SSDs über ein Jahr lang ausgewertet:
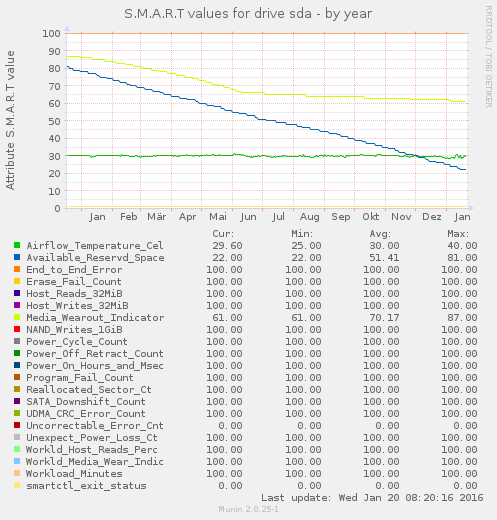
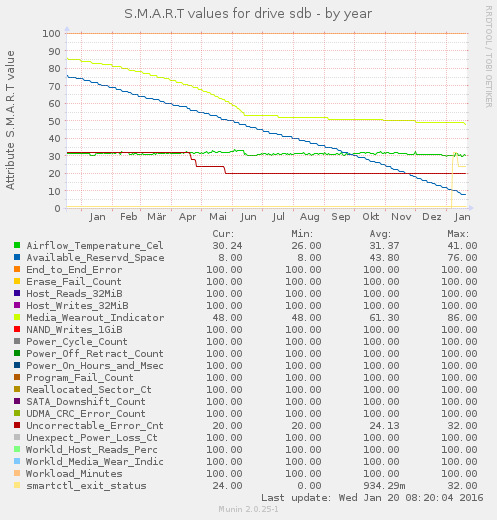
Schön zu sehen ist, wie der Reservespeicherplatz permanent abnimmt. Bei der zweiten SSD sieht man, dass obwohl noch Reservespeicherplatz vorhanden sein sollte, nicht korrigierbare Fehler plötzlich sprunghaft ansteigen.
Die SSDs wurden über das ganze Jahr gesehen durchschnittlich mit 170 kB/s Lesen und 713 kB/s Schreiben "gequält". Auf dem Server lief eine eher kleine Webseite und ein zusätzlicher Dienst, welcher oft viele Daten schreiben musste. Beide verwendeten MySQL, welches mit InnoDB Speicherpages schreibt und zwecks Transaktionssicherung auch immer einen Flush auf den Plattencache machen muss.
Da viele Hoster dedizierte Server mit HDD und SSD nur "entweder oder" anbieten, sollte man vorher genau überlegen, ob eine SSD für die eigene Serveranwendung und auf lange Sicht überhaupt geeignet ist.